
PDFをダウンロードさせずにブラウザで表示させる
はじめに
情報の取り扱いがシビアな企業ですと「PDFファイルをダウンロードさせたくない」という要望があります。
ダウンロードできてしまうと、ファイルの転送や印刷が容易なため、できればブラウザ上だけで1ページづつ表示させたい、というニーズです。
今回は弊社のクラウドサービス「店番長」に10月8日のアップデートで実装した「PDFをファイルとしてローカルに保存させずに、ブラウザ上で閲覧する」方法について解説したいと思います。
≫続編『PDF.jsで解像度を変更し、ぼやけの問題を解消する方法』はこちら
実装方法① PDFのOpenParameter を使う(要件に合わなかった手法)
「PDFをブラウザのプレビュー機能で表示させ、ツールバーを非表示にする」という方針でまずは確認です。
ブラウザキャッシュには入りますが、「明示的なダウンロードは避けられ、印刷も不可能にできる」という仮説で、調査を始めました。
実際にツールバーを非表示にしてみます。
サンプル:(Adobe公式PDF open parameterの解説PDFが開きます)
https://www.adobe.com/content/dam/acom/en/devnet/acrobat/pdfs/pdf_open_parameters.pdf#toolbar=0
#toolbar=0 を記述するだけなので非常に簡単です。
ツールバーの他にも、スクロールバーや、表示するページも制御できます。(詳しくはドキュメントをご覧ください)
ただ、ツールバーは非表示になりましたが、次の問題が発生しました。
- ブラウザの右クリックを使うと、保存・印刷ができてしまう
- Windows以外のOSでは、パラメータ付与によるツールバーの制御が効かない
これでは要件は満たせません。その後、iframe、embedタグなどHTMLタグでも検証しましたが、やはり問題は解決しませんでした。
これらの検証結果から、別の手法の検討が必要になりました。
実装方法② "PDF.js" を使う
GitHubに"PDF.js"のドキュメントおよびモジュールが存在します。
PDF.jsを使ったサンプル:
https://mozilla.github.io/pdf.js/web/viewer.html
では、ここからは具体的な実装方法です。
ドキュメントのHello World using base64 encoded PDFを元に、実装を行います。
- PDF.jsの初期化
var pdfjsLib = window['pdfjs-dist/build/pdf']; pdfjsLib.GlobalWorkerOptions.workerSrc = '//mozilla.github.io/pdf.js/build/pdf.worker.js';
- PDFデータの読み込み
var loadingTask = pdfjsLib.getDocument({data: {PDFデータ(base64形式)} }); loadingTask.promise.then(function(pdf) { pdfDoc = pdf; renderPage(pageNum); }); - PDFレンダリング
function renderPage(num){ pdfDoc.getPage(num).then(function(page) { var viewport = page.getViewport({scale: scale}); var renderContext = { canvasContext: ctx, viewport: viewport }; var renderTask = page.render(renderContext); renderTask.promise.then( function () { console.log('Page rendered'); } ); }); }
以上です。
静的ページでの検証は、上記のように実装すれば割とあっさり完了です。
問題発生
これでいけるとWEBに組み込んだところ、javascriptエラーが出て全く動かない状態になりました。調べてみると、pdf.worker.jsの初期化に失敗していることが判明しました。どうやら単純にライブラリへのパスが通っていなかっただけで、 pdfjsLib.GlobalWorkerOptions.workerSrc にpdf.worker.jsのフルパスを指定することで初期化が成功し、無事問題を回避できました。
pdfjsLib.GlobalWorkerOptions.workerSrcを指定しない場合は、pdf.jsと同じところにあるpdf.worker.js を参照するようです。
何より、エラーメッセージがわかりやすいため、焦らず対応できました。
たとえば、pdf.jsとpdf.worker.jsとが互換性のないバージョンの組み合わせになってるなども、下記のように一目でわかります。
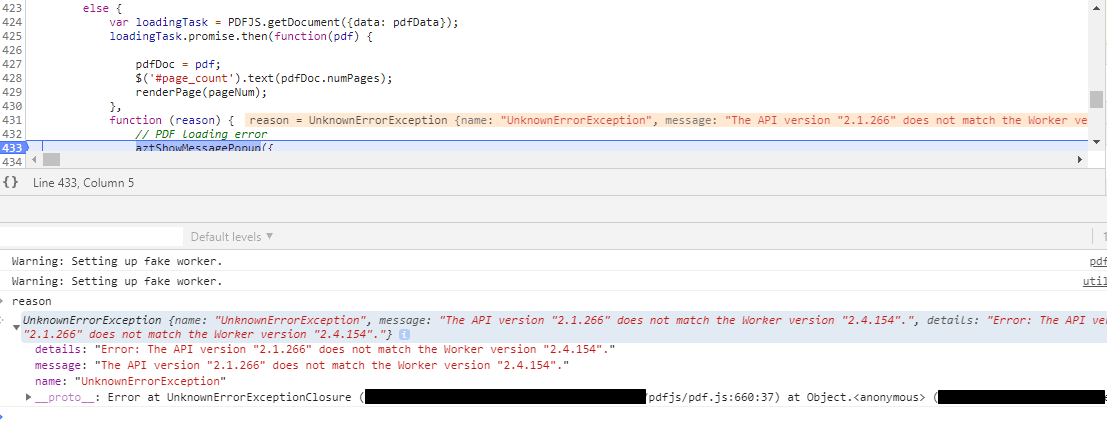
もうひと仕上げ
実はPDF.jsでは、PDFをレンダリングした画像の上に、PDFの文字を color: transparent; として透過で配置しています。このため、一般的なPDFビューアーのように、文字をコピーして引用することができます。しかし、今回のニーズでは引用はむしろ必要ないため、テキストレイヤーの実装はあえてしませんでした。
ご参考までにテキストレイヤーを実装したい場合、追加の記述は以下の通りです。
まず、追加でjsファイルとcssファイルを読み込みます。
PDFのレンダリング後にテキストを取得して、テキストレイヤーを作成します。
page.render(renderContext)
.then(function () { return page.getTextContent(); })
.then(
function (textContent) {
var textLayerDiv = document.createElement("div");
textLayerDiv.setAttribute("id", "text-Layer");
textLayerDiv.setAttribute("class", "textLayer");
var containerDiv = document.getElementById({pdfのcanvas});
containerDiv.appendChild(textLayerDiv);
var textLayer = new TextLayerBuilder({
textLayerDiv: textLayerDiv,
pageIndex: page.pageIndex,
viewport: viewport
});
textLayer.setTextContent(textContent);
textLayer.render();
})
透過しているテキスト部分を選択し、無事にクリップボードに取得することができました。
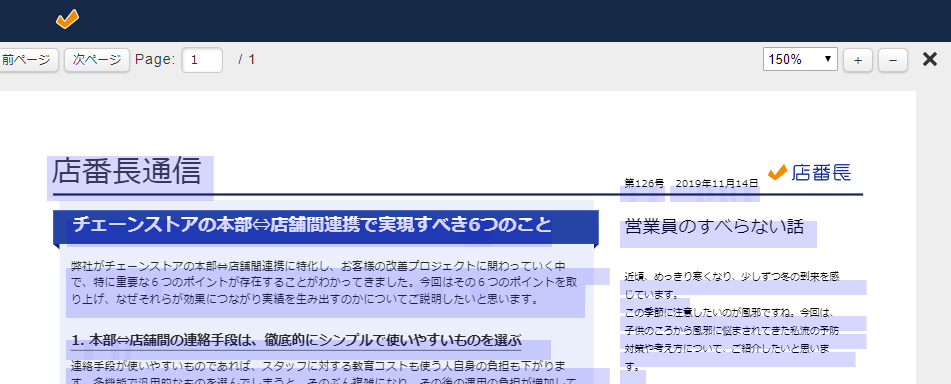
完成
Windows / macOS / Android / iOSの主要ブラウザ最新版で一通り動作検証を行い、問題なく表示されることを確認しました。これでデバイスに依存せず、PDFリーダーも必要なく、どの環境でも同じ制御下で閲覧することができます。また、PDFファイルを持ち出すことができなくなり、文字の選択も不可能なため、文字を引用しての共有や印刷も制御できました。
さいごに
スクリーンショットは防止できていません。頑張って1ページごとにスクリーンショットを撮ればコピーはできてしまいますが、この方法はPDFに限らずどんなファイルや表示方法でもほぼ回避できないので、今回の対策はカジュアルな持ち出しや印刷を防ぐ目的でこのスコープまでとしました。
追記
続編『PDF.jsで解像度を変更し、ぼやけの問題を解消する方法』もよろしければご覧ください。
参考資料
店番長リリース
https://www.linkcom.com/miseban/news/20191008/
PDF Open Parameter
https://www.adobe.com/content/dam/acom/en/devnet/acrobat/pdfs/pdf_open_parameters.pdf
PDF.js
ソーシャルメディアで最新情報をお届け